
Conclusions

The sport of ultra-running is one of the fastest growing international sports - participation in the sport has increased by 1,676% over the past two decades. Each year, tens of thousands of people find their way to the start line of races that exceed the traditional 26.2 mile marathon distance. With increased popularity, there will inevitably increased financial interests and incentives. As the sport continues to evolve big corporations are becoming more and more involves in the sport. Recent years have seen massive investments from global brands such as Nike and Adidas. Such brands are trying to capitalize on a trail running apparel / gear market that currently exceeds $10 billion. This valuation in expected to double over the next 10 years. Major investments are centered around athlete development and race prize money to increase athlete incentives. Secondly, large investments are being funneled into race development and media broadcasting to support the sport’s public outreach. With increased financial and public interest in ultra-running, deciphering race performance is of paramount importance.

Record sponsorship deals were signed in 2024

Public and fan interest in the sport has grown dramatically
This project was able to effectively begin to unravel the intricacies of ultra-running. The project began by compiling data from multiple sources including multiple API pulls. This data compiling resulted in one of the most comprehensive race results datasets ever created in the sport. The dataset eventually consisting of over 55,000 race results with around 20 different relevant feature categories. Results are included from historical races as far back as the late 1800s. Athlete features include everything from, finishing time to age and gender. Race relevant features include everything from, race elevation and distance statistics to complex race day weather data. After the cleaning and compilation of such a thorough dataset preliminary data analysis provided a launching point for further analysis. It was determined that primary features of interest included, athlete gender, age, finishing time, finishing position, race distance, race elevation gain, race entrants, and maximum temperature were of particular relevance. As such, these were the primary features explored in this analysis.
To begin the process of understanding how ultra results are related unsupervised machine learning techniques were applied to the data. As outlined in the models and methods portion of this project, principal component analysis, clustering, and association rule mining was applied to the compiled comprehensive dataset. Principal Component Analysis (PCA) is an unsupervised machine learning method commonly used to reduce the dimensionality of data. By applying PCA to a relevant dataset subset the dimensionality of data was effectively reduced from 6 to 3 while retaining over 70% of the variability in the data. This transformation speaks to the multicollinearity between ultra-running statistics. Furthermore, clustering techniques of kmeans, dbscan, and hierarchical were then applied to PCA transformed data. Due to the complex nonlinear relationships within the data kmeans struggles to create meaningful clusters while hierarchical clustering was able to effectively classify race results based on time on course. Association rule mining was also applied to the data subset to uncover hidden relationships with in race statistics. This analysis produced expected rules such as the relationship between long distance races and long finishing times. However, this analysis also uncovered unexpected rules such as relationships between athlete genders and the amount of elevation gain in a race. The applications of unsupervised machine learning methods illuminated unexpected relationships and patterns within ultra-marathon data.
After performing unsupervised machine learning methods the project switched to examine supervised machine learning methods. This approach focused on binary classification of race distances – exploring how well models could be trained to classify a race result as either being from a 50 mile or 100 kilometer race. This process examined how consistently separable and classifiable race data is. This exercise produced results that will be very useful and replicable for future result predictions as well as for filling in incomplete data. For this analysis the subset of data was split into training sets (80% of the data) with which to teach the model and disjoint test sets (20%) with which to evaluate model perfomance. The analysis examined multiple models (Naïve Bayes, Logistic Regression, Decision Trees, and Support Vector Machines) and parameter refinements for each model. The analysis conducted determined that an entropy based decision tree had the highest ability to accurately classify race results. This model accurately classified a perfect 100% of the 1,820 items in the testing set. The tree models far outperformed other supervised predictive models, but are often susceptible to overfitting data. A radial basis function (rbf) support vector machine with also performed very well in this predictive classification task. This SVM accurately classified 97% of test items and is likely more replicable than the decision tree model. The project also touched on the concept of ensemble predictive learning to reduce individual model biases. By applying an ensemble boosting technique the performance of a gaussian Naïve Bayes model was drastically improved.
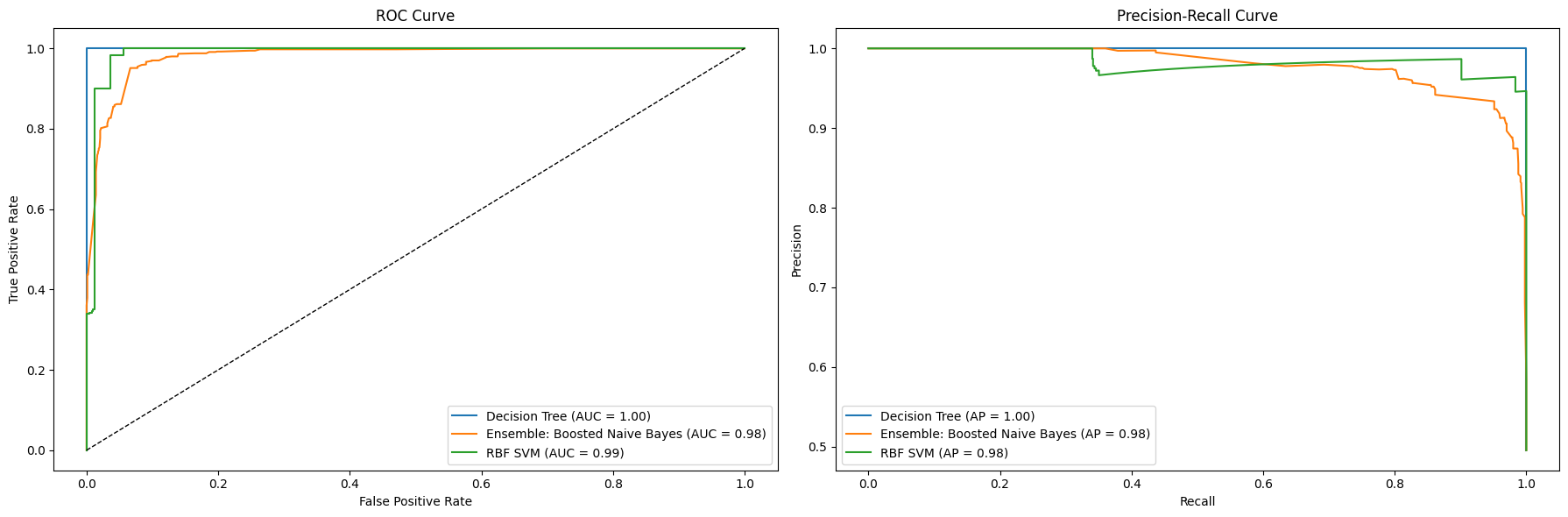
Performance comparison of the best predictive models
Overall, this project proved very successful in laying the groundwork for complex data analysis and machine learning in the sport of ultra-running. The analysis conducted has illuminated complex underlying relationships between important race and athlete statistics. In addition to assisting in athlete development, these uncovered patterns will prove very useful to large organizations in equipment development and race creation. Furthermore, the supervised machine learning classification analysis established a powerful launching point for any future predictive testing. This exercise demonstrated the ability for machine learning models to effectively predict race results as well as fill holes in incomplete datasets. Moving forward with future ultra-running related predictive modeling entropy-based decision trees and RBF support vector machines with high cost parameters should be the primary models of choice. Additionally, ensemble methods should be implemented to eliminate individual model shortcomings. As ultra-running continues to explode in popularity and gain major financial investment, understanding the mechanics of success in the sport will be increasingly valuable. This analysis has laid the foundation for future study. Furthermore, it has effectively demonstrated the power that machine learning can have in the assessment of ultra-marathon data.