Ensemble Learning
Introduction
Ensemble learning is the method in machine learning of combing predictions from multiple different models to make the final classification decision. By picking say the majority decision from a variety of models set with different parameters, ensemble methods can avoid biases that exist in individual models.
In the classification problem repeatedly explored through out this project of attempting to predict whether or not a specific race observation is from a 50 mile race or a 100 kilometer race, the ensemble learning method can be extremely valuable. For example, as discussed in previous sections many models often had a bias to over-predict one length race or the other. By applying an ensemble learning approach to this problem, these biases can be eliminated. As a result, ensemble models will often exhibit much higher performance metrics when compared to singular predictive models.

Visualization of ensemble learning (boosting)
For the following analysis the ensemble technique of AdaBoost will be applied to Gaussian Naive Bayes models. This technique of boosting is the process of training models successively where every new model focuses on the mistakes made by the previous model. Through this iterative process model weaknesses can be filtered out.
Data Prep
The ensemble learning AdaBoost gaussian naive bayes model will use the same data as used in the Naive bayes classification. This includes data that is numeric and continuous. Furthermore, 80% of the data has been dedicated to the training set, while the other 20% has been left to test the model performance.

Snipit of pre-prepared data

Snipit of prepped data to be used in ensemble learning

Snipit of training data to be used in ensemble learning
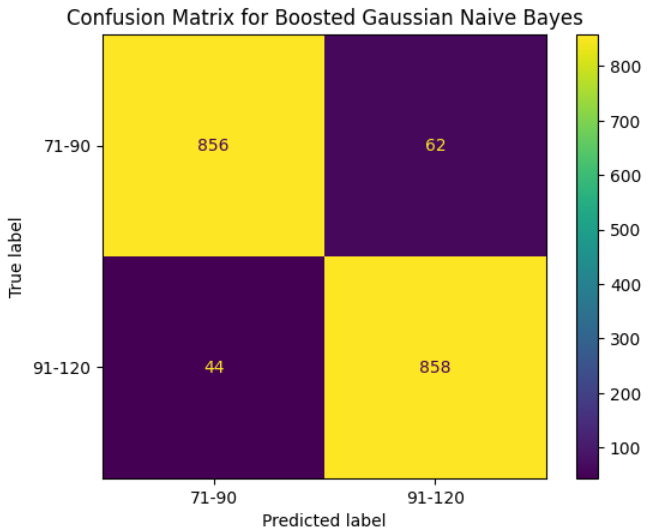
The AdaBoost gaussian naive bayes model produced the displayed confusion matrix (right) and corresponding classification report. Comparing these outputs to the previously explored outputs from the traditional gaussian Naive Bayes model, it is clear that the ensemble learning approach improved model classification performance. The previous model had an accuracy score of 87.3% this was greatly improved through the ensemble method to 94.2% this consisted of 125 more properly classified race observations.
This example of applying to ensemble learning clearly illustrates the potential benefits of this approach to predictive modeling. By applying ensemble learning techniques to race result distance classification biases will be reduced and model predictive abilities will be greatly enhanced.

Snipit of test data to be used in ensemble learning
Model Results